What is a web request?
A web request is a request we make to the server from the client in order to start a conversation with the server so that we can get the data we need.
A typical web request looks something like this

Protocol:
According to Wikipedia, the Hypertext Transfer Protocol (HTTP) is an application protocol for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web, where hypertext documents include hyperlinks to other resources that the user can easily access, for example by a mouse click or by tapping the screen in a web browser.
To simply put, a protocol is a set of rules to follow in order to send data.
Network Location:
Network location is the address of our server location. Computers identify themselves using IP addresses, hence we need an IP address to connect to the server. But it’s hard to remember the IP address of each website on the internet. To solve this particular problem we come up with DNS servers.
A DNS server stores IP addresses with their respective strings. Whenever we make a web request, our browser sends the network location string (giriaakula.com) to the DNS server and the DNS server returns the IP address of that particular server. Now, the browser has an IP address of the server.
Path & query
We now know the address of the server (IP address) and rules (protocol) through which we have to contact the server. But when we contact the server we need to request something from the server either it is an HTML file or something else. That’s where the path comes into play. We are requesting something from this specific path in the server. Here we are requesting from ./blog.
Through query, we can send data to an application. A typical query looks something like this
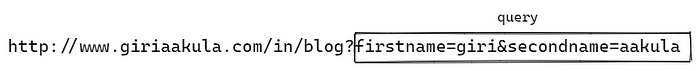
Queries are typically followed by a question mark and separated by an ampersand.
Port:
In general, we don’t specify ports. This is because most of the servers use default ports. A port is a communication endpoint in a particular system. Consider this scenario, you have two applications running on your system on localhost. How are you gonna access a particular application? You are now at a collision. To solve this problem we have something called ports. We run our first application at port 1000 and our second application at port 2000. Now we can access two applications without any collision

We don’t specify ports while accessing web pages on the internet because the internet uses default ports which is 80 for HTTP and 443 for HTTPS.
Now we know what a web address and what it consists of. Let’s look at what happens when we hit enter after entering the web address.
NETWORKING:
To simply put, when we enter the web address in our device it is going to hit our nearest router. It is a wifi router when we are accessing the web through wifi router or an ISP when we are accessing the web through ISP provider especially through mobile devices. Either way, we are going to hit a router. The router then takes our data and passes it through the internet to the destination computer. This is what happens on the outer layer. Let’s try removing these layers and understand what happens inside it.
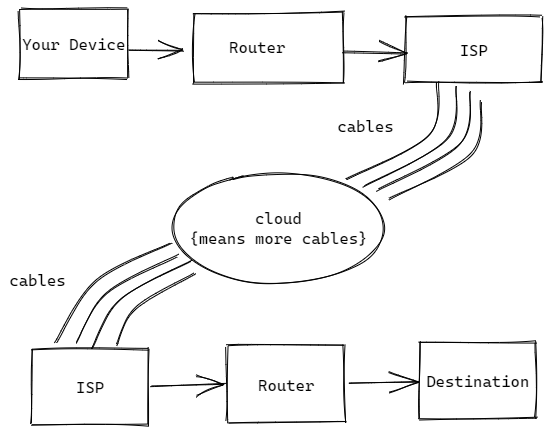
PROTOCOLS:
As we discussed earlier protocols are just a set of rules to follow in order to establish communication. To establish communication over the internet we have Interner Protocol. Every electronic device which has to do with the internet has one. A typical IP address is of 32 bits in size.
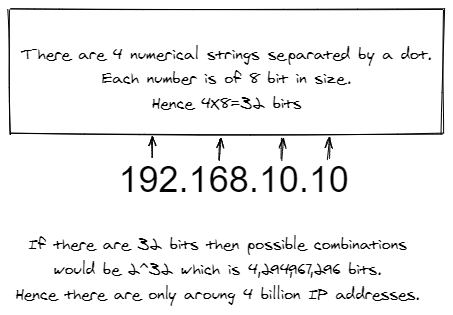
The above-mentioned IP address is of version 4 or IPv4. We have IPv6 which solves this particular problem and it is been there since the late ’90s and it is been slowly accepted and implemented by the global community.
But, the problem with IPv4 still remains and we solve this using a technique called NAT or Network Address Translation. To understand NAT we have to first understand more about IPv4. There are two types of internet protocols, public and private. Private protocols are IP’s which most internet-connected electronic devices have. They usually start with 192.xx.xx.xx and 10.xx.xx.xx.
They are limited and they can be duplicated, means in a network there may be multiple devices with the same IP address. When we connect to wifi, the router does NAT for us. Router converts our device private IP to some complex string and sends over the internet and it maintains a nat table to do that.
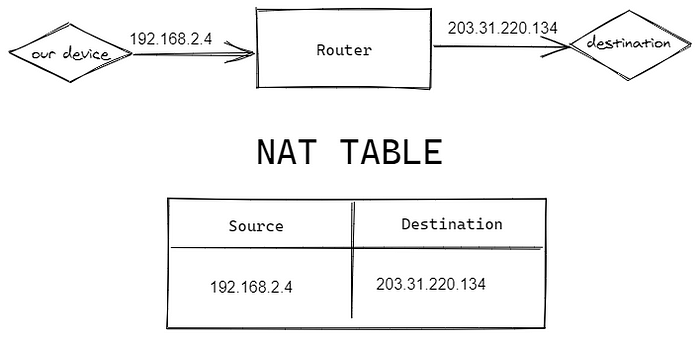
The above explanation neglects a few elements for simplicity sake. If you really want to know about NAT, I suggest you read this article.
If you can observe we are sending our data through our private IP and router converts it to some string and pass it to the destination. Now, whenever the response from destination comes router checks in the NAT table to which device the response have to be routed.
IP is good enough to connect between two computers in a perfect world. But we are not living in a perfect world. If we send some data to some computer sitting over a few thousand kilometres away, then there is no guarantee that the data we send reach the destination without any losses. Data has to be travelled through physical wires and wires are not 100% efficient. To overcome this problem scientists come up with another protocol on the top of internet protocol.
Transmission Control Protocol (TCP)
To understand TCP we have to first understand the science behind sending data. Let’s say we are sending a file of 10mb to someone over the internet. Our computer breaks this 10mb file into data or network packets. Each packet is of size 1kb to 1.5kb. Each packet has headers which carry sequence number, source IP, destination IP and some other details.

Hence our computers sends 10,000 packets to send 10mb. The destination computer receives all the 10,000 packets and arranges them back by using sequence numbers that we put on headers of each data packet.
Let’s say for some reason a packet was lost during the travel. This means we have lost the whole file because of one packet. Here comes TCP to save us. In TCP the destination computer sends an acknowledgement for each packet it receives. Using this the sender computer can verify if the packet was successfully received or not if not it is going to resend that particular packet again.
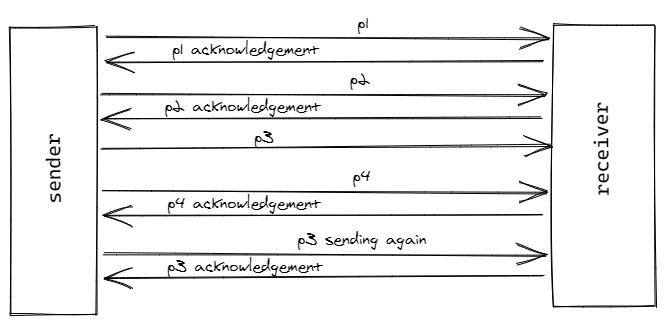
In the above picture, we can see that the acknowledgement for p3 was not received but p4 was received. Now, the sender assumes that the p3 may be lost and it resends p3 again. HTTP was built on top of TCP.
Refer to this article if you want to know more about protocols and the network layers.
What a packet consists of?
Each data consists of around 1kb of data. That means 1000 bytes. Each byte consists of 8 bits. Means 1000 bytes equal to 8000 bits. A bit may be either 0 or 1. Or we can say on or off. Means either the power is present or not.
How we send data through a wire?
In order to understand how the data travel through a wire. We have to first understand what is current, how it passes through a wire.
What is current?
Current is the flow of electrons over a material.
What are electrons?
Electrons are generally called as subatomic particles. We all know that an atom is the smallest unit of matter that forms a chemical element. An atom consists of electrons, protons and neutrons. Generally, electrons revolve around the nucleus and nucleus consists of protons and neutrons.
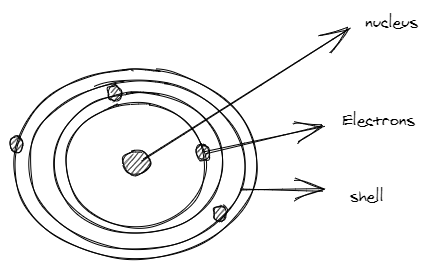
Electrons that are present in the outermost shell (also known as orbit) are called valence electrons. Electrons are negatively charged and protons are positively charged. Outermost electrons are generally loosely bound to the nucleus, means they can be easily displaced. A typical one-metre length copper wire consists of thousand of billions of these atoms. Whenever there is some kind of force acting upon it electrons present in the outermost orbit get freed. Now, the outer orbit is empty for that atom and one electron is roaming freely. If we again apply some force more free electrons get generated and these free electrons are attracted by the nucleus of atoms with more protons. Here we can see that electrons are moving from one atom to another in the presence of force. This force is called voltage and the movement of electrons is called current and the materials which allow electrons to flow freely are called conductors.
We can imagine current as water flowing in pipe and voltage as pressure that we apply on the pipe to push water far.
![]https://miro.medium.com/max/450/0*fVCCsEL11p8En0SU.jpg)
As we now know that we can manage the number of electrons flowing through the wire at a particular time. If the electrons are present consider it as 1 and if the electrons are not present consider it as 0.
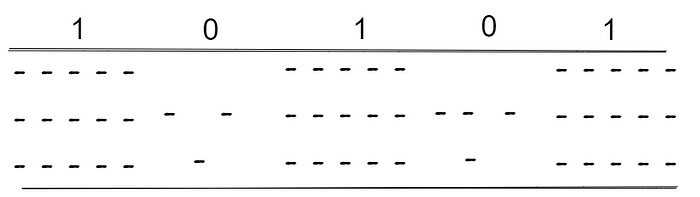
This is what happens in a normal cable but in optical fibre cables, we use light to represent. It is pretty straight forward if the light is present it is 1 if not 0.
This whole complex process happens under the hood when you make a web request. This article is heavily inspired by this talk.